

감성 대화에서 지식 추론까지
생성형 AI의 산업화·일상화 주도
SK텔레콤(SKT)은 지난 21일 과학기술정보통신부가 추진한 '독자 인공지능(AI) 파운데이션 모델' 프로젝트 참여하면서 지난 2018년 한국어 특화 AI 기술 연구를 시작으로 지속한 AI 자립의 노력이 구체적으로 실현되는 계기를 마련했다고 24일 밝혔다.
SKT는 이미 한국어에 최적화된 거대언어모델(LLM)을 독자 기술로 개발·운영하는 등 국내 AI 생태계의 기술 자립을 이끌고 산업 전반에서 실질적으로 활용하기 위한 기반을 꾸준히 구축해오고 있다. 아울러 감성 대화, 통화 요약, 지식 기반 응답 등 다양한 분야에서 생성형 AI 기술을 고도화하며 이를 실제 고객 접점에 지속적으로 적용하고 있다.
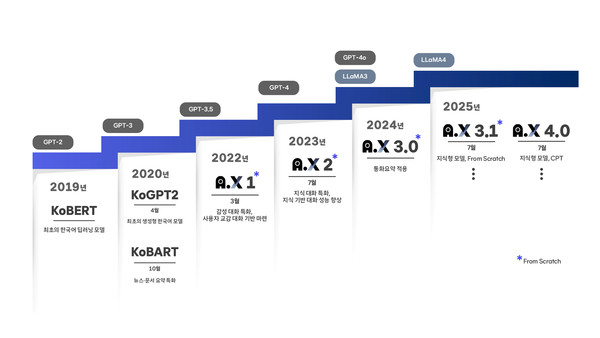
SKT는 지난 2019년 국내 최초의 한국어 딥러닝 언어 모델인 'KoBERT'를 자체 개발해 공개하고 이를 고객센터 챗봇 등에 적용한 바 있다. KoBERT는 기존 해외 모델과 달리 한국어의 조사, 어순, 띄어쓰기 등 언어 구조를 반영해 문맥 이해와 의미 분석에서 높은 정확도를 보였다.
2020년 4월에는 국내 최초로 GPT-2를 한국어로 구현한 'KoGPT2'를 공개했으며 같은 해 10월에는 뉴스·문서 요약에 특화된 'KoBART'를 출시하는 등 지속적인 기술 개발로 자연어 처리 역량을 향상했다.
SKT는 개발 기술을 상용 환경에 적용하기 위한 고도화도 병행했다. 지난 2022년에 자체 개발한 GPT-3 기반 한국어 특화 버전을 에이닷(A.) 서비스에 적용, 사용자 요청에 따라 일상 대화와 다양한 작업 수행이 가능하도록 구현했다. 이어서 감성 대화에 특화된 'A.X 1' 모델을 추가 적용해 정서적 교감 기능을 강화했다.
2023년에는 복잡한 문맥 이해와 지식 기반 응답이 가능한 'A.X 2'을 선보였고 2024년에는 새로운 아키텍처를 기반으로 추론 속도와 전반적인 성능을 향상시킨 'A.X 3.0'을 공개했다.
SKT에 따르면 A.X 1부터 3.0까지 모든 모델은 구조 설계부터 데이터 수집·학습까지 모든 과정을 SKT가 직접 수행한 '프롬 스크래치' 방식으로 개발됐다. 대규모 한국어 데이터를 기반으로 단순한 질의응답을 넘어 사용자 의도·맥락을 파악해 보다 논리적이고 유용한 대화가 가능하다.
이달에 공개한 'A.X 4.0'은 외부 지식 기반 추론 기능이 대폭 강화됐고 대규모 학습(CPT) 방식으로 학습돼 데이터 보안, 로컬 운영 가능성, 한국어 처리 효율성 측면에서 강점을 갖췄다. SKT는 비슷한 시기에 70억(7B)와 340억(34B) 파라미터 규모의 두 가지 'A.X 3.1' 모델을 프롬 스크래치 방식으로 개발해 공개하기도 했다. 두 모델 모두 추론 모델로의 확장 가능성을 고려해 코드와 수학 성능을 대폭 향상시켰다.
이처럼 SKT는 독자 기술을 기반으로 한 A.X 3 계열의 프롬 스크래치 모델과 CPT 방식의 외부 지식 학습을 적용한 A.X 4 계열의 대규모 모델을 병행 개발하는 '투 트랙 전략'을 추진 중이다. 향후에도 한국어에 최적화된 LLM 기술을 지속적으로 고도화하고 초거대 AI의 산업화·일상화를 선도하며 국내 AI 생태계 활성화를 위한 기술 공유·협력을 확대해 나갈 계획이다.
김근정 기자 / 경제를 읽는 맑은 창 - 비즈니스플러스